
This is an overview of a new cryptocurrency reporting platform proposed called crypto statto
The web...
read more

Lowering the cost of ownership of a website and the Software Development Life Cycle
The hardest thin...
read more
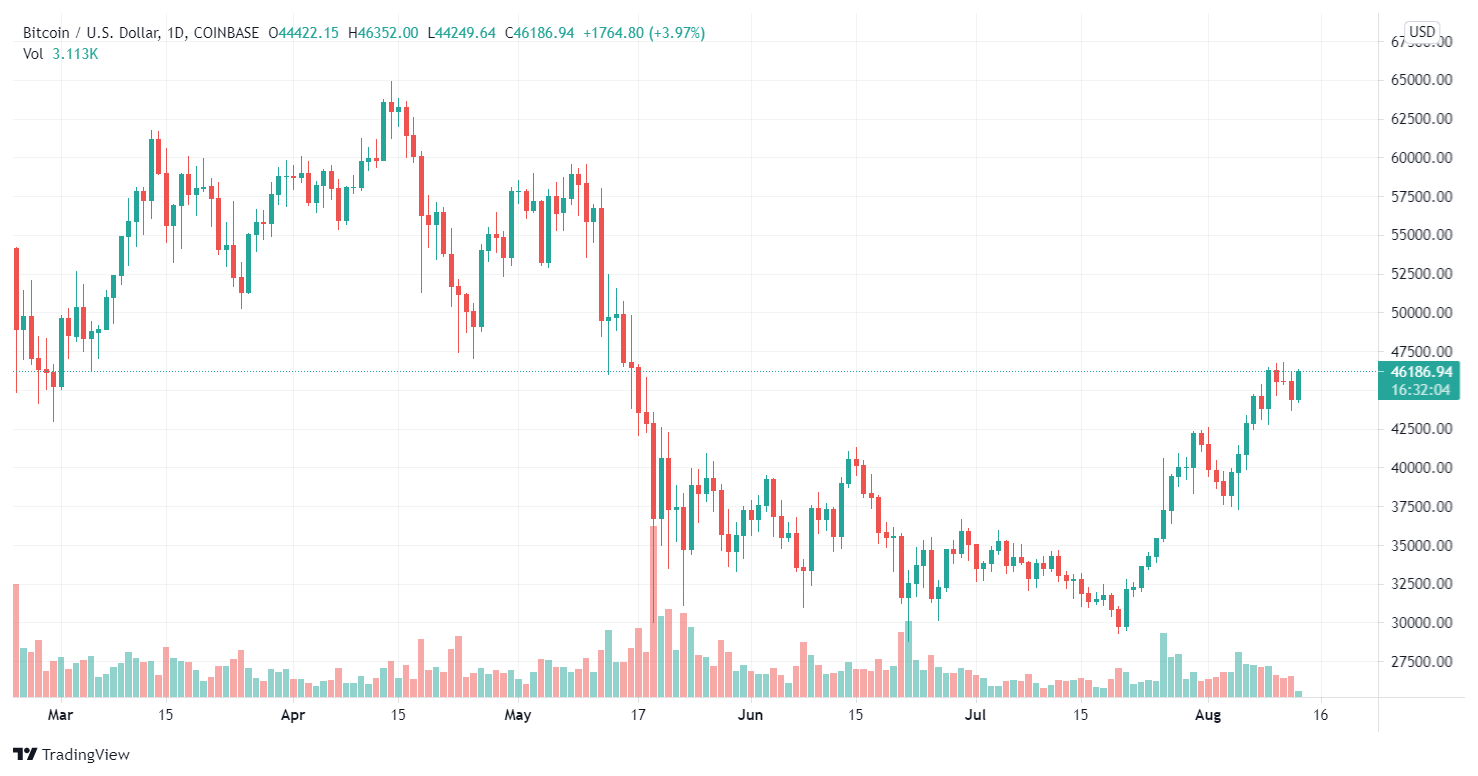
I want to focus on explaining a strategy I employ to grow cryptocurrency capital. There are several ...
read more
Relatively late to the cryptocurrency market in Summer, 2017, I lived through the epic peak of the B...
read more
First and foremost, this is not financial advice or guidance on how to trade. You can lose all your ...
read more

Disclaimer: This is not financial advice or a recommendation to go out and do anything to do with cr...
read more
Medium of exchange, unit of account, store of value.
There is a basic function of money which makes ...
read more
Running the below results in an error. Am still trying to understand why this should be the case? Ok...
read more
I have an agreement with coincentral to redistribute articles for free, I think will be useful ...
read more

Not being a skiing instructor, having little in the way of style or elegance but having significant ...
read more